
CollectiveCrunch makes use of such data in combination with satellite data and AI to model inventories in the Northern European market and suggests the adaptation of its solution in Latin America.
This blog post presents a technical background on standards used by forest machines to record operational and production data. It also presents the role of the Nordic forestry sector on the development of such standards, and argues that its usage by CollectiveCrunch’s Linda Forest technology enables more accurate and updated forest inventory predictions.
Technical Background
In a fast-paced and competitive world, access to accurate and timely information has become paramount for any company. Information provides the basis for assertive decision-making, enabling faster adaptation to market and regulatory changes. When it comes to forestry, it is no different. Companies face an increasingly competitive and dynamic environment, with the additional push for more sustainable practices while meeting ever-growing market demands.
Forest management and planning rely on data that reflects the state of forest assets in the field and the available operational resources. Managers must have a clear understanding of the production cycle in order to devise feasible forest operations. Historically, data to support forest management has been collected in field campaigns using sampling techniques. Field campaigns measure different aspects of the forest production cycle, such as forest inventories and time-tracking of forest operations. The data collection process has always been a crucial yet time-consuming and expensive operation in the forestry sector. On top of that, field sampling too often fails to fully characterize what is being measured, delivering expensive, incomplete, and possibly biased measurements.
The growing mechanization of the forestry sector fundamentally changed the way we measure and monitor forest operations. Since the late 70’s, chainsaws began to be replaced by harvester machines equipped with modern computers, sensors, and software. The machines are now capable of measuring fuel consumption levels, productive time and even structural attributes of harvested trees, such as lengths and diameters of individual logs. This mechanization process opened up a new range of possibilities to quickly collect data, derive information, and produce knowledge about forest operations.

Harvester machines are capable of measuring fuel consumption levels, productive time and even structural attributes of each harvested trees.
During the 80’s, Nordic forestry companies were already using data collected by harvest machines. At this point, there were no standard protocols of communication between machine sensors and computers. The need for a standardized protocol resulted in the creation of the Standard for Forest machine Data and Communication (StanForD) by an initiative of public and private companies in the late 80’s. Since then, the development and maintenance of StanForD has been coordinated by the Forestry Research Institute of Sweden (Skogforsk) along with its network of global and local partners.
The first version of the standard, known as StanForD Classic, is implemented through a collection of light-weight binary files encoded into the ASCII format. Bundled together, these files act as an interface to configure operations and to store production data.
The access to standardized data was a step-change for the sector, enabling the creation of scalable machine-agnostic analysis and software that pushed companies to an unprecedented digitalization stage. Nevertheless, as the sector evolved it became clear that a more intuitive, comprehensive, and modern file structure was needed. In 2006, a project to develop a new standard was started. After five years, a new standard following a modern, scalable and powerful XML format that provides more flexibility to both developers and end users was defined in early 2011. The new version, known as StanForD 2010, quickly reached the market and became the de-facto standard used by all major machine manufacturers around the world.
Just like the Classic version, StanForD 2010 is composed by a series of files that configure and store operational and production data. In total, the new standard implements 19 different files, called messages, that are tailored to standardize machine control, production reporting, quality assurance and operational monitoring. The messages are handled by the onboard software which saves them hierarchically into memory using different filename extensions. The use of each message is dependent on the harvest method and the sensors available.
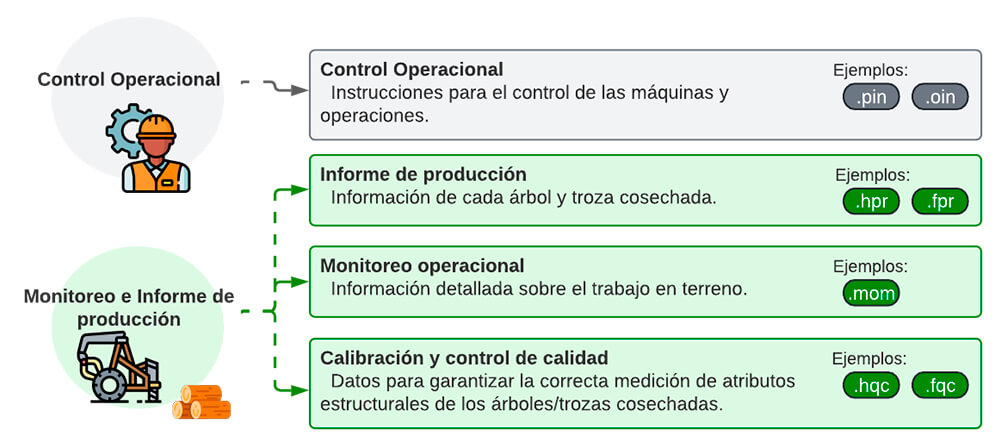
StanForD 2010 file structure.
Once field operations are through, forest managers can feed StanForD messages to data management and analytics systems to gain information and knowledge about their forest operations. This data provides invaluable answers to a broad set of questions that could not be addressed in a straightforward and meaningful way before the mechanization of the forest production cycle.
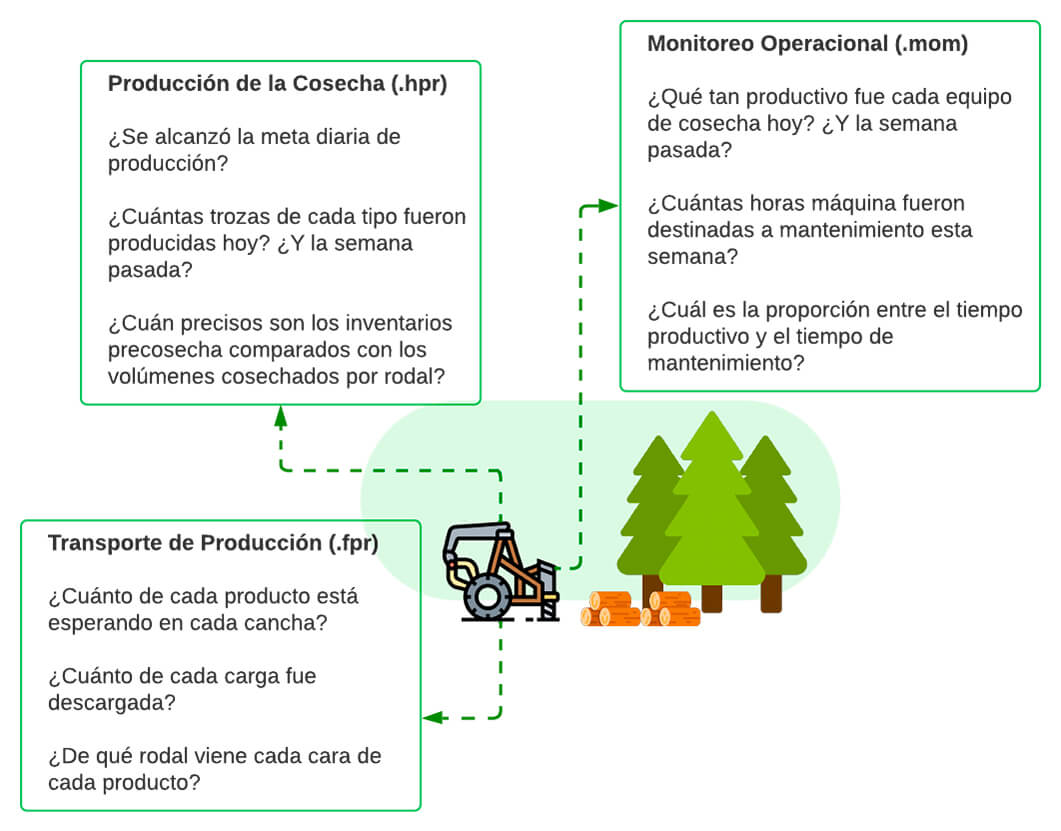
Examples of questions that may be addressed with StanForD 2010 messages.
Harvester Production Report (HPR) data
Beyond operation insights and control, harvester sensors provide unprecedented insights into wood volume and biomass harvested from each stand. Production data, saved into the Harvested Production Reporting (HPR) message, specifies diameters, lengths and GPS coordinates of each harvested tree. Metadata detailing the harvest site, machine parameters and operation conditions is also recorded. HPR data is widely used in Nordic countries for harvesting reporting and monitoring. In Finland for example, all timber sales are based on measurements extracted from HPR data.
In addition to harvest monitoring and reporting, tree-level positional and structural data allows the creation of 3D representations of the stands as they were just before the harvest. This information can be used to validate field inventories and even generate virtual field plots to create and verify model-based forest inventories.

Tree-level data extracted from an HPR message and aggregated into a regular grid. Blue circles represent harvested stems, while grid colouring showcases tree density variation in the stand.
Harvester data in Latin America
Driven by emerging ESG agendas and the need for higher productivities, Latin America companies are actively developing and promoting new technologies and sustainable practices.
Forestry companies operating in Latin America rely on a skilled workforce and state-of-the-art fleets of forestry machines that are able to record operational and production data. This data is being used by some companies to manage forest operations, such as time-tracking (productive/idle machine time), fuel consumption, and productivity monitoring.
In Nordic countries, mobile network coverage in remote areas allows machines to automatically transfer data to databases using 4G connection. In Latin America, the lack of network coverage in rural areas prevents instant data transfers. This fact is described by several companies as the main challenge holding back a full-scale digitalization of forestry operations in the country. While 4/5G connection does not become a reality, local companies are extracting machine data using flash drives, dedicate mobile apps, or satellite and radio connection systems to monitor operations even in real-time.
Although some initiatives exist, harvester data usage, especially HPR data, is not widespread yet. Challenges to utilize HPR data range from difficulties with data handling and processing to field logistics related to sensor calibration and data transfer. By overcoming these barriers, Latin American forest companies could benefit from incorporating HPR data into forest inventory design and implementation.
Virtual plots derived from HPR data are a valuable source of information to predict different forest attributes, such as tree height and wood volume, in model-based approaches. The combination of such data with remote sensing and artificial intelligence delivers highly accurate and updated forest inventory predictions, by reducing sampling errors introduced by traditional methods. Predictions of wood volumes could be further optimized by incorporating environmental parameters (e.g., soil, terrain, climate) and forest management practices (planting, fertilization and thinning patterns) into the modelling steps.
Our Proposed Way Forward
CollectiveCrunch is a global leader in forest inventory systems, combining remote and ground data sources to derive better predictions. Our solution makes extensive use of harvester data as described above. Currently, the solution covers more than 18 million hectares of Northern European forests, serving 7 of the top 10 European forestry players. Automate your harvester data processing and enable easy integration to all your forest data systems with CollectiveCrunch HPR offering.
We specialize in taking your raw stream of data, unpack and structure it for easily understandable analytics to your GIS environment and onto our Linda platform. Instead of field sampling as the basis of payment, take advantage of all the available data sources. Get paid for what’s there in a forest by improving your understanding with verifiably more accurate forest inventories and reduce the need for field visits.
We suggest bringing this proven solution to the Latin American market and make wide-scale use of HPR data. This will provide the local forest industry with higher-accuracy inventories that drive better decisions and profitability.
Summary of benefits of Linda Forest:
- More accurate inventories using a combination of remote and ground data sources.
- Added value to pre-existing data sources like historical sampling data.
- Potential use of historical lidar data reduces the need for future scans.
- Lower inventory costs by reducing the need of future lidar scans and field sampling.
- Fewer sample plots mean less human measurement errors and issues with lack of skilled field staff.


